

CUDA Kernel Grid, Block, and Thread Structure
Published: Feb 8th, 2024
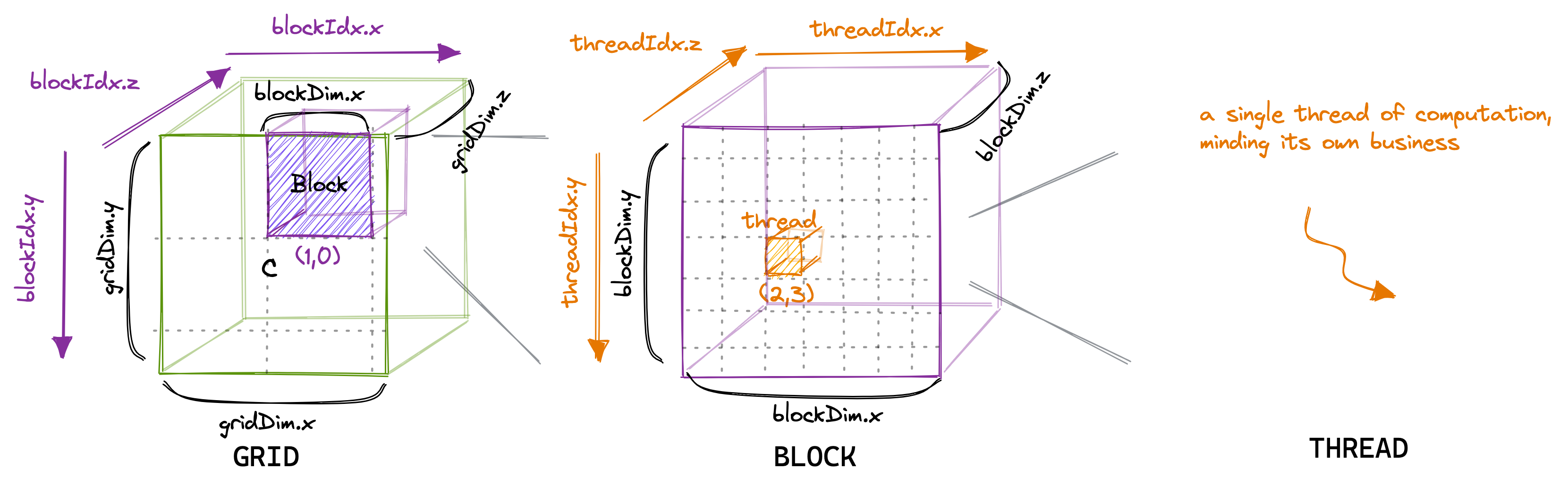
NVIDIA's CUDA technology introduces a hierarchy of thread organization that is pivotal in exploiting the parallel processing capabilities of the NVIDIA hardware. This article aims to clarify how CUDA kernel invocations shape the grid and blocks structure and how developers can control thread configurations within blocks using the 'blockDim' variable.
Kernel Invocations and Grid Structure
When a CUDA kernel is invoked, it spawns a new execution grid composed of multiple thread blocks. The grid serves as the top-level structure for organizing threads in a way that reflects the GPU's capability to execute many threads in parallel. Each block within the grid can house up to 1024 individual threads—although this maximum limit is subject to change with newer generations of GPUs and can be verified by consulting the latest CUDA Programming Guide.
Block Composition and Shared Memory
Threads within the same block have the unique advantage of being able to communicate through a shared memory region colloquially known as SMEM. This low-latency memory space is exclusive to the block, allowing threads to exchange data rapidly without resorting to slower global memory transactions. Access to shared memory is synchronized, ensuring that data integrity is maintained throughout the block's execution lifetime.
Configuring Threads per Block with 'blockDim'
The configuration of threads within a block is flexible and can be tailored to the demands of specific applications. This is achieved using the 'blockDim' variable, which is a three-component vector of type 'int'. It defines the dimensionality (x, y, z) of each block within the grid. By adjusting these values, developers can optimize performance based on factors such as memory constraints and the nature of the algorithm being implemented.
// Example of a kernel invocation with block dimension configuration
__global__ void myKernel() {
// Kernel code here
}
int main() {
dim3 blockDim(16, 16, 1); // Configure a block of 256 threads (16x16)
int numBlocks = ...; // Determine the number of blocks required
myKernel<<>>(); // Invoke the kernel
cudaDeviceSynchronize(); // Synchronize the device
return 0;
}
To summarize, the CUDA programming model provides a hierarchical and efficient thread organization that is paramount for achieving parallelism on a GPU. Through careful configuration of grid and block dimensions, notably via the 'blockDim' variable, CUDA programmers have precise control over the execution of their kernels, enabling them to harness the compute power of GPUs for a variety of complex computational tasks.





:max_bytes(150000):strip_icc()/Capella-58d150333df78c3c4fc42549.jpg)



